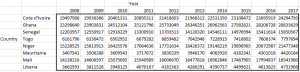
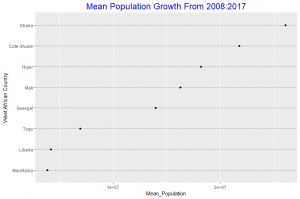
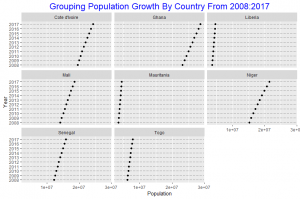
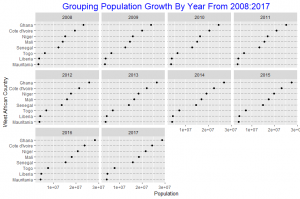
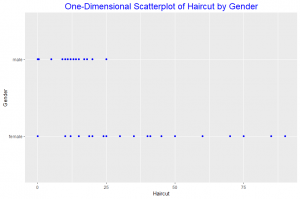
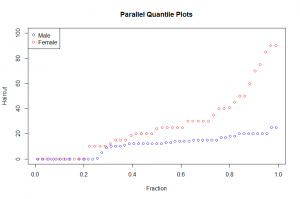
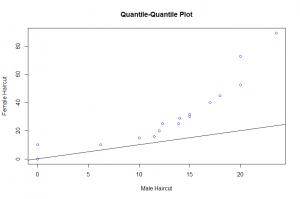
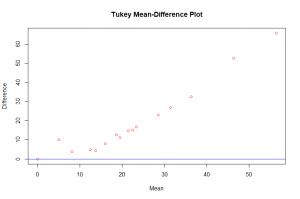
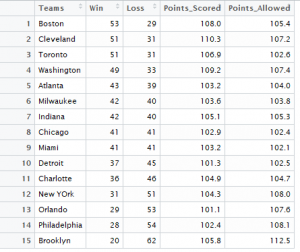
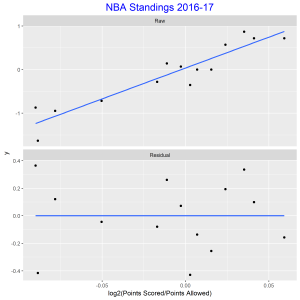
In this post I will be presenting scatter plots overlayed with Loess smoothing curves and their residual plots. Data generated from a simulation is used for the plots.
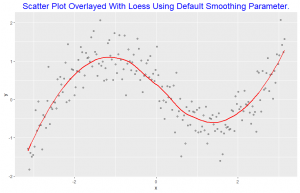
This scatter plot is overlayed with loess smoothing curve with the default smoothing parameter of 0.75.
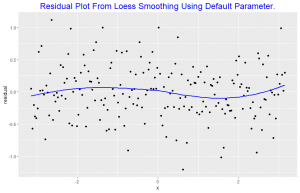
The residuals are graphed against x and a loess curve is superposed; for the curve on this display, alpha = 0.8. The loess curve suggests there is some dependence of the residuals on x, since the curve is not nearly horizontal. This means the default smoothness parameter is too large in the smoothing of the scatter plot above. This indicates that the loess curve has not effectively found the signal.
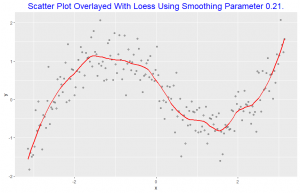
The scatter plot is overlayed with loess smoothing curve with smoothness parameter of 0.21
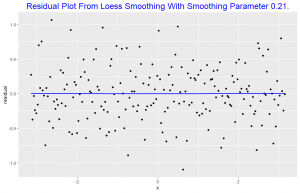
This plot shows no dependence of the residuals on x, since the loess curve is horizontal. This suggests the loess curve with smoothness parameter 0.21 overlayed on the scatter plot is not distorting the underlying pattern. This indicates that the lowess curve has effectively found the signal. For the loess curve in this plot alpha = 0.8.