Last week, you worked on loess smoothing and we’re talking about graphing time series data this week. It seemed worthwhile to give you a personal example of smoothing a time series.
Back in 2007, I wrote a book that illustrates computation using R for my Bayesian class (MATH 6480). I have a website where I have information about the book and Google Analytics has been keeping track of all of the people who have been visiting the site.
I downloaded a file that gives the number of visitors for each day from the first (November 30, 2007) through the day I collected the data (March 16, 2013). (This is total of 1934 days.) I am interested in the pattern of counts over time.
1. I first tried graphing the counts as a function of day number.
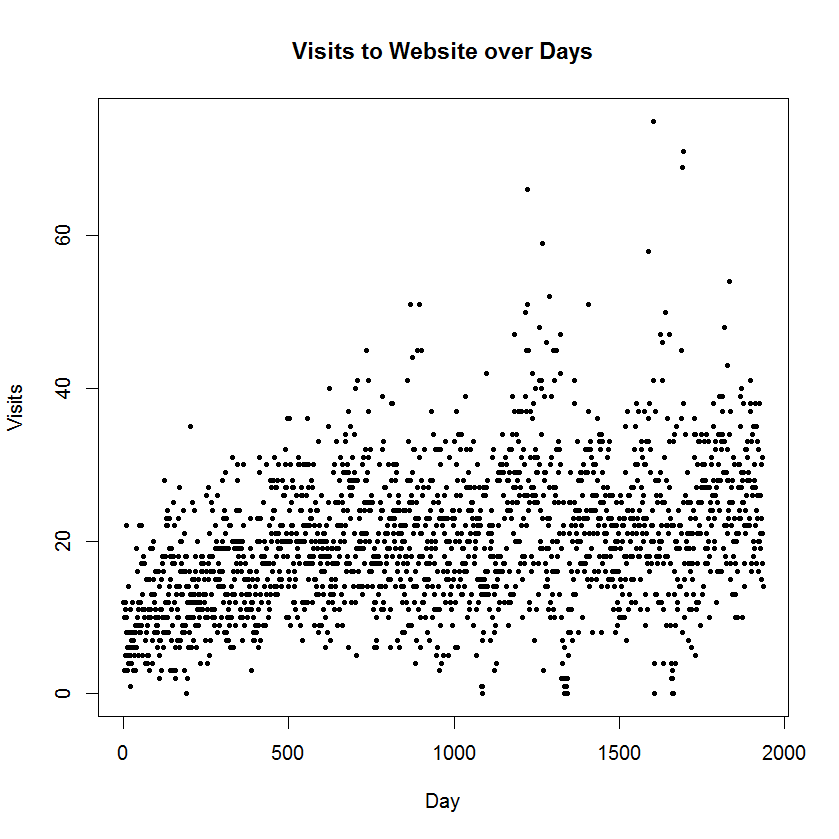
Note that I changed the plotting character to a solid dot (pch = 19) at a smaller size (cex = 0.5). I didn’t find this plot that illuminating due to the large variability across days. I know from previous exploration, that there is a drop off in counts over weekends and special times. Anyway, it is tough to see the pattern across days.
2. My next thought was to collect counts over weeks instead of days. This would help smooth over some of the day-to-day variation that I don’t care about. I collapsed the data over 276 seven-day periods and I plot the count over week number. I added a loess smooth to see the pattern. I played with different smoothing fractions until I did not see any pattern in the residual graph.
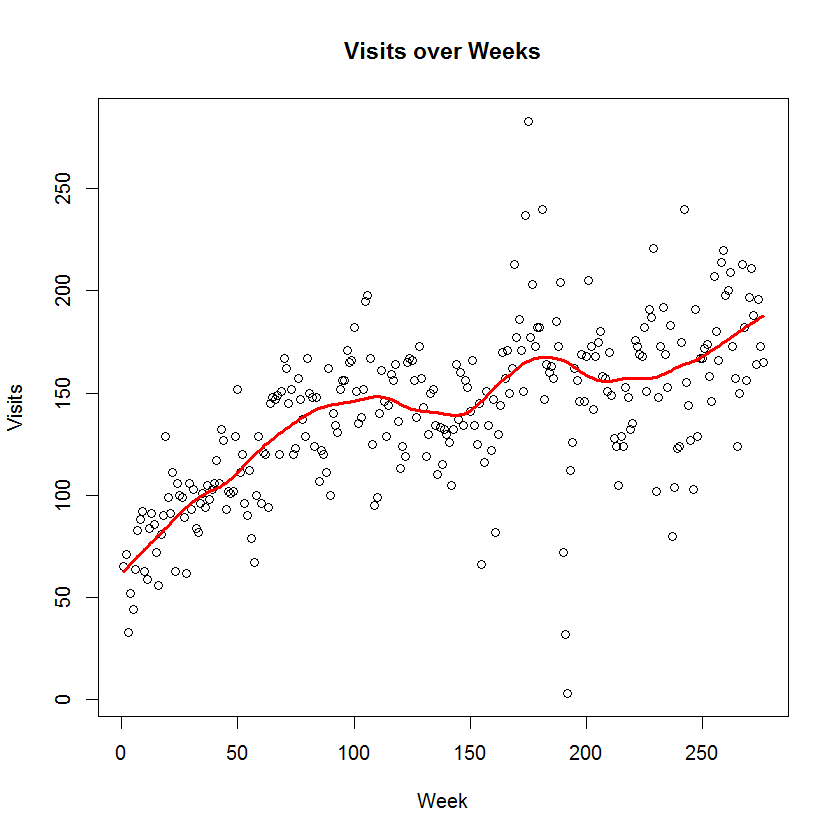
What is the pattern of visits? I see steady growth in the visits until Week 100, steady counts from Weeks 100 to 150, another period of growth between Weeks 150 and 200, a little drop off around 200, and a gradual growth from Week 230 to the current week.
Actually, some of the pattern makes sense to me. The original book was published in 2007 and I came with a revision in 2009 — this might explain the growth around Week 150. I was fortunate that both Bayesian thinking and the use of R have shown increasing popularity in recent years.