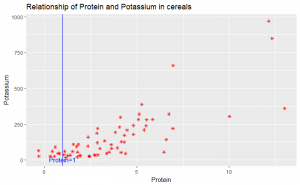
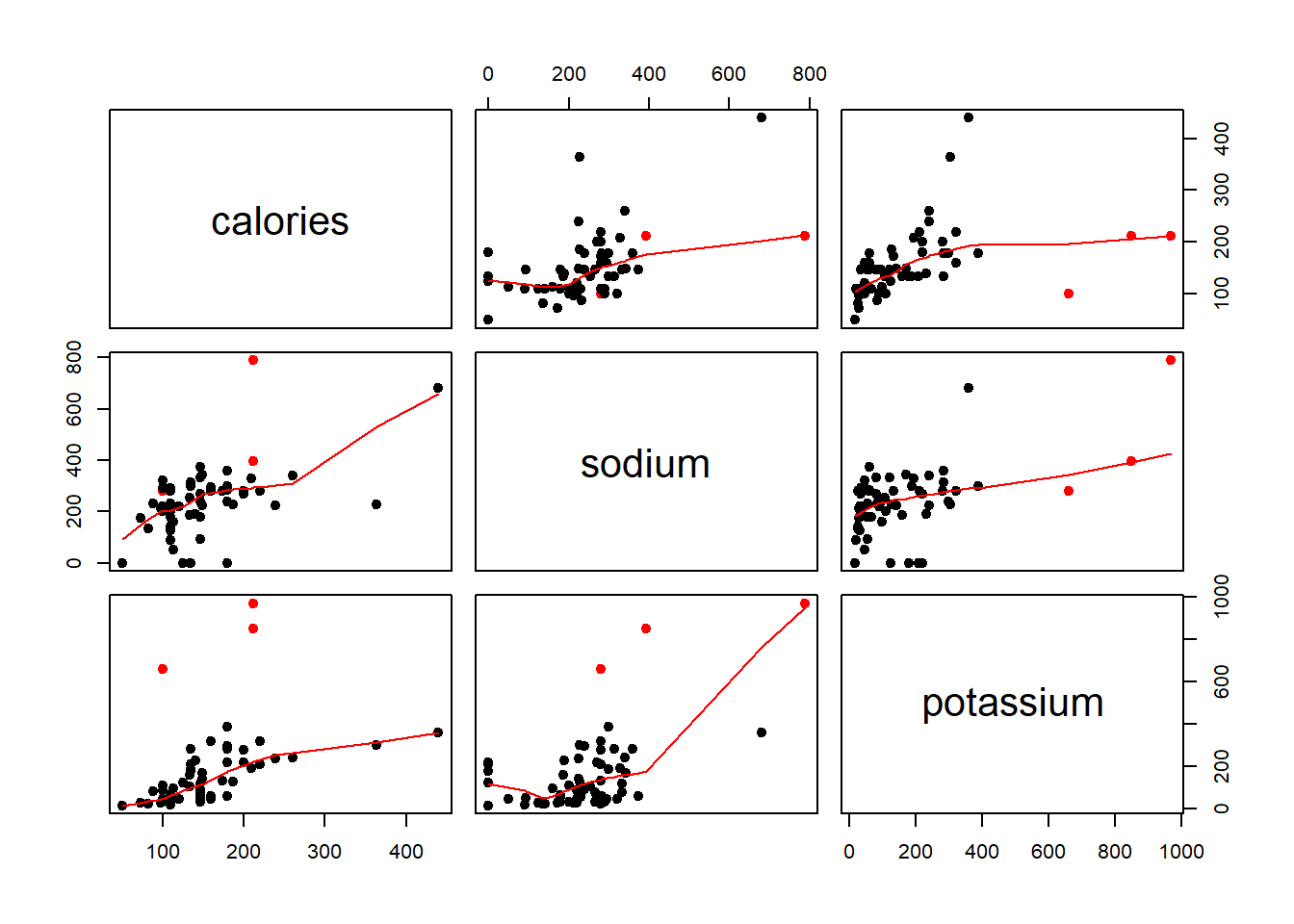
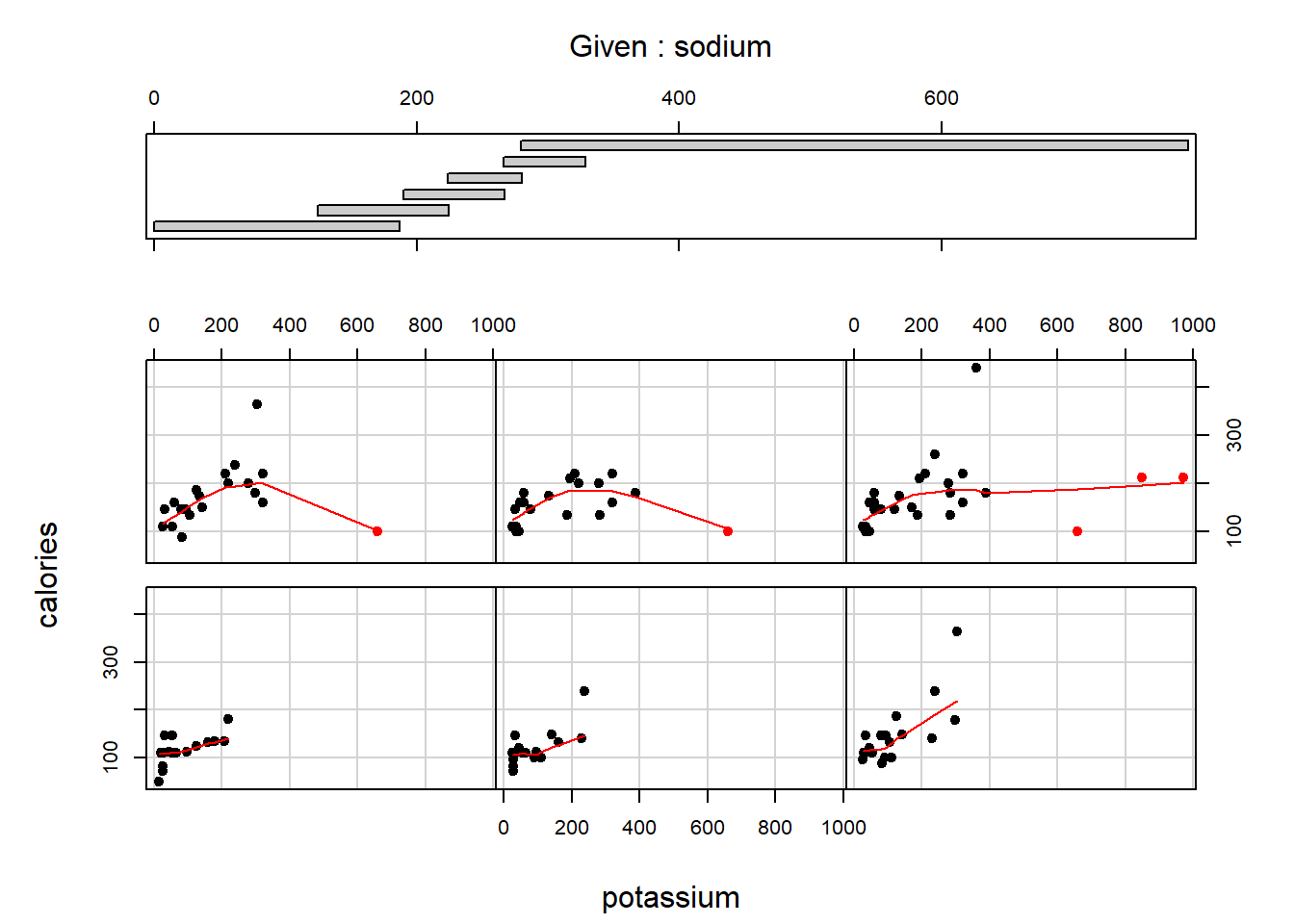
The dataset studentdata from the LearnBayes package contains results from a survey given to a large group of students from a introductory statistics class.
I took a random sample of 100 from the data and looked at the number of shoes owned by the men and women in the class. From the sample we generated, there are 59 females and 41 males.
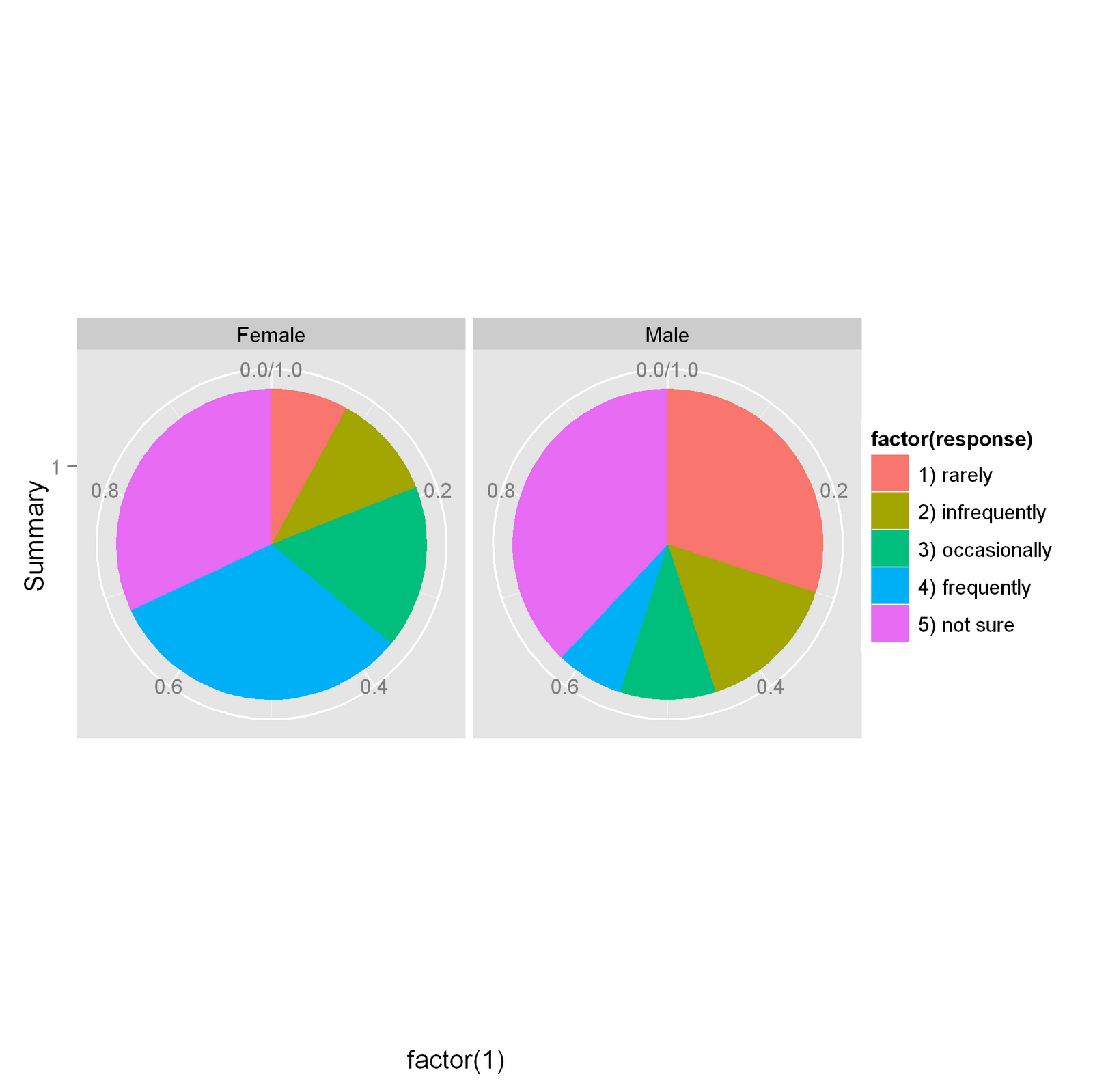
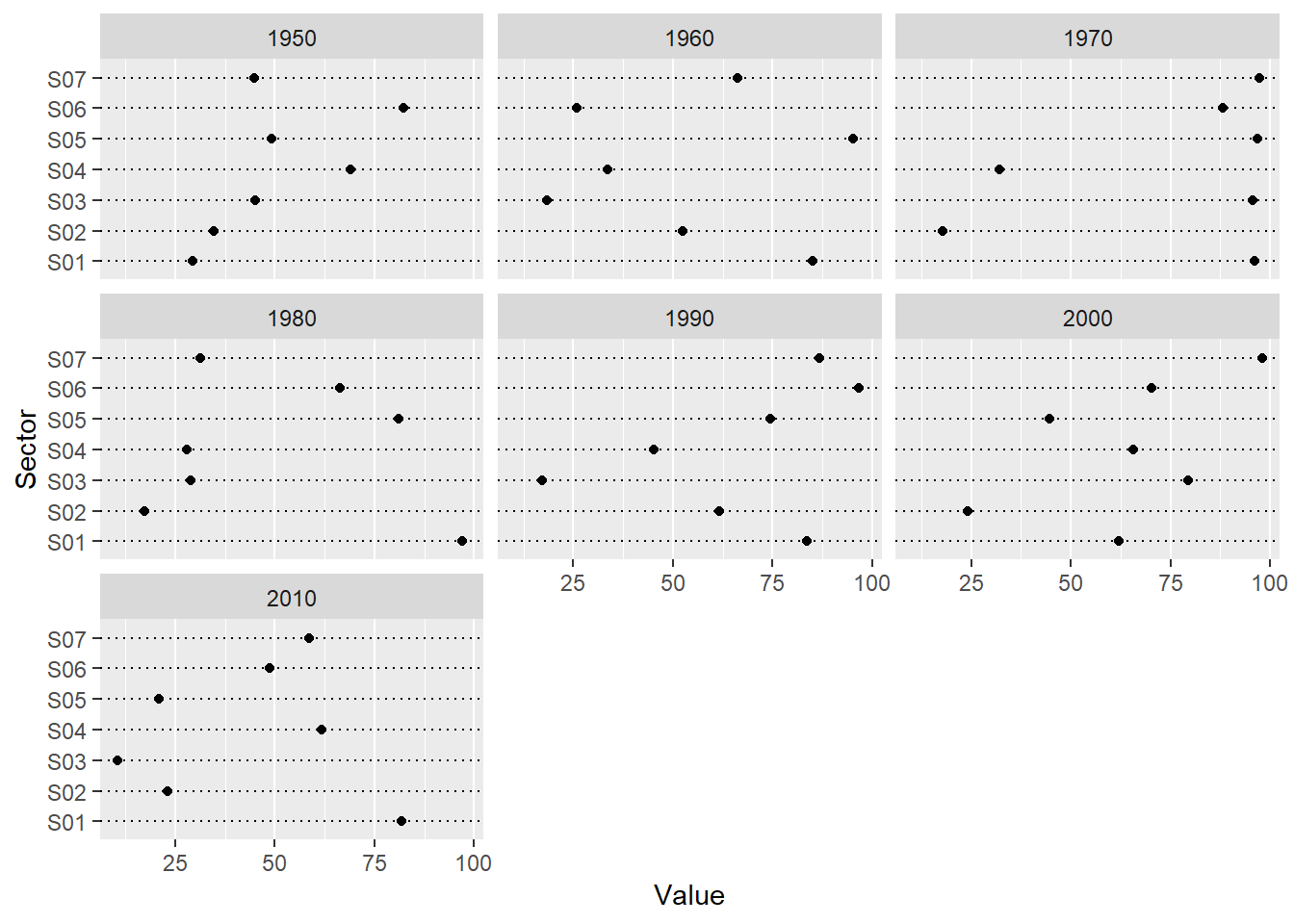
Parallel one-dimensional scatterplots of the variables by gender:

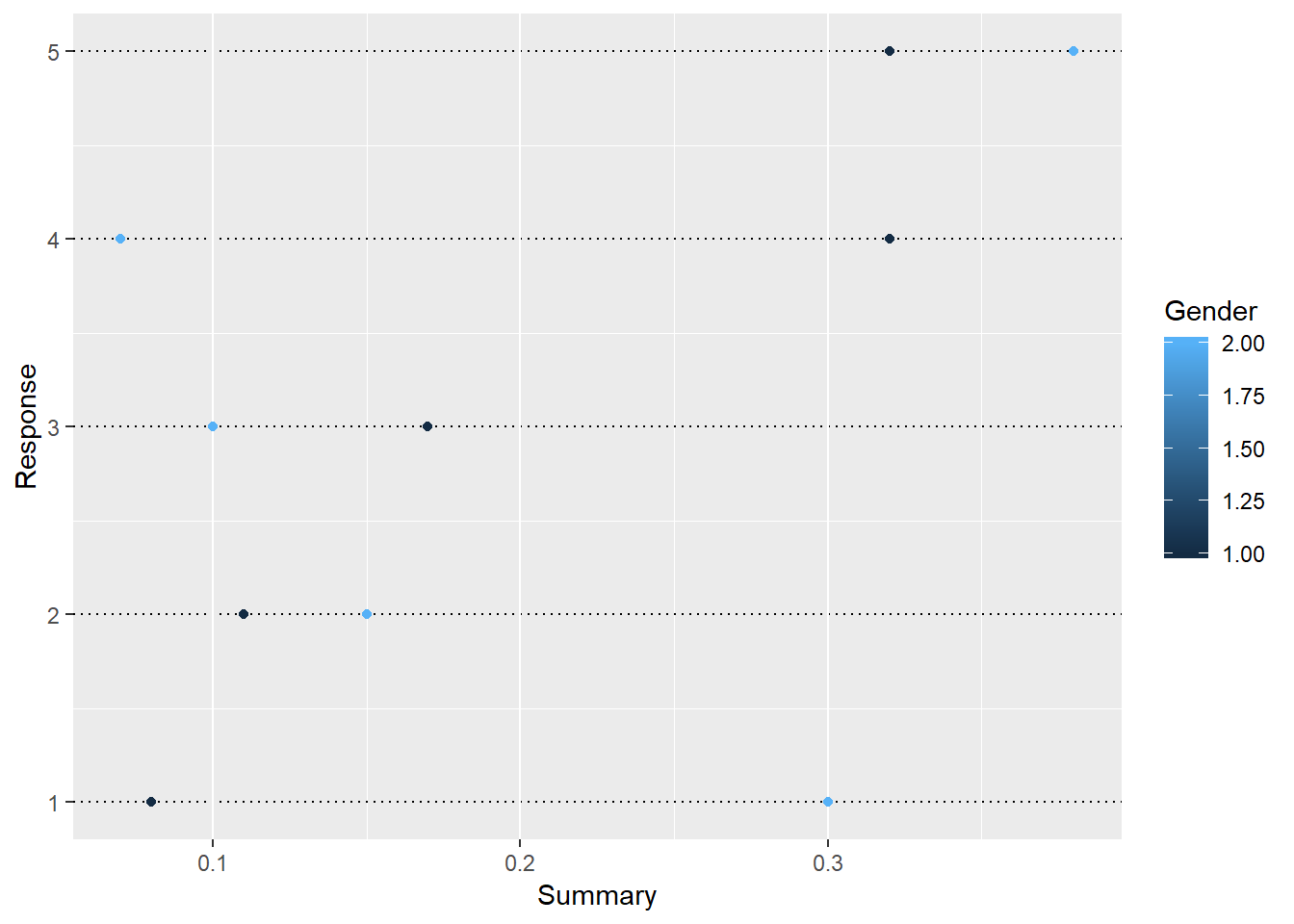
Parallel quantile plots of the male values and of the female values:

The x-values are representing the fractions of the haircut prices from the smallest to largest with the value (i-0.5)/59 for female which are in black, i=1……59, i is the order in the group of females; (j-0.5)/41 for male which are in red, j is the order in the group of males. The y-values are representing the haircut prices. So we clearly see what’s the quantile for each haircut price in terms of gender by this graph.
Quantile-quantile plot of the male and female values:

Tukey m-d plot from the quantiles of the two samples:

The average difference of haircut prices between females and males are around 15.4, from this graph we observed that the difference between males and females are always negative which indicates the haircut prices are always higher than women, and one interesting thing is that the difference generally increases as for higher haircut prices.
In conclusion, the Tukey Mean-difference plot is the best to provide the graphical comparison of the haircut prices of these two groups. We clearly see all the differences are negative and more important, there is a roughly linear trend of the differences over the average haircut prices. As haircut prices increases, the difference tend to increase as well which is not that apparent in other graphs.













 The formula of best fit is given by “lm” method as: log(W/L)=13.76*log(PA/P) which implies the corresponding Pythagorean formula is W/L=(PA/P)^13.76.
The formula of best fit is given by “lm” method as: log(W/L)=13.76*log(PA/P) which implies the corresponding Pythagorean formula is W/L=(PA/P)^13.76.