
STATA for data analysis
Stata is a software product created by the StataCorp in 1985. It is a general-purpose statistical software package. It assures a fast, convenient, accurate tool for data handling, data manipulation, visualization, statistical modelling, and reproducible reporting. It is primarily used by researchers and academicians in various fields including but not limited to economics, social sciences, biomedicine etc. Stata provides a very user-friendly interface having different options through its menu feature for carrying out analysis of the data. It has therefore found imminence in dissertation work of researchers owing to its multiple capabilities of conducting data research work on http://uniresearchers.co.uk/.
Important Features of STATA for Likert scale analysis
Likert Scale
The responses of surveys conducted to measure the attributes of attitude, beliefs, and opinions are often measured using a set of Likert Items. A Likert item is a statement which a respondent is asked to provide input based on some objective or subjective requirement. It usually suggests the degree of agreement or disagreement of the respondent towards the question or statement presented. A typical 5-point Likert scale ranges from responses of “Strongly Disagree” to “Strongly Agree”.
Data Handling
Stata’s data management feature gives extensive control to the user. It can import and export the data into different formats and can also manage data coming from different databases simultaneously. It also provides functionalities to sort, join, match, merge, create and append data. Therefore, raw data available from a source can be easily manipulated for further analysis. In addition to that, new data when available can be easily appended to the existing data. A representative GUI of the data view in Stata is shown in Figure 1.
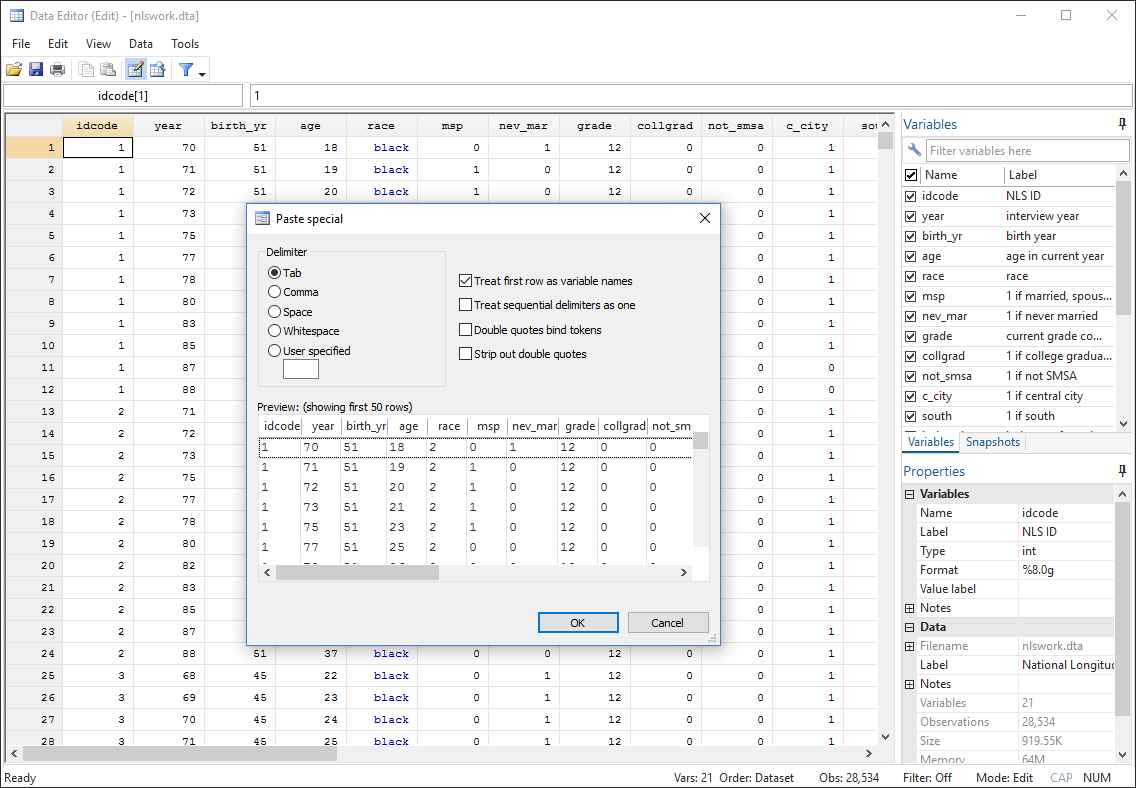
Fig. 1: Data Editor of Stata tool (adapted from ww.stata.com)
Statistical features and graphical capabilities in Stata
Stata allows the user to either refer to the menu item or write custom codes for performing an analysis of the Likert scale. There are primarily two data tabs in Stata: Statistics and Graphics. Within the “Statistics” option there are a total of 21 sub-tabs listings a plethora of options for statistical analysis. Specific to the Likert scale analysis, the user can choose to perform various parametric and non-parametric tests based on the data, as well as Cooper’s z test, Whitney t-test, or Hsu’s Chi-square test, and many such other techniques.
Therefore, irrespective of the nature of dissertation study and the type of Likert data involved there is an appropriate method available to apply on the data for the desired outcome. Similarly, within the “Graphics” tab, there is also a listing of 21 sub-tabs to choose the appropriate display medium. Though this may sound daunting to some to choose from such a wide variety of options, Stata provides a very helpful guide to sort this problem for the user. In the command window, the user can just type “help principal component analysis” for example, and detailed documentation on the principal component analysis method opens to aid the user. The next figure, Fig. 3 gives a few snapshots of the publication-ready graphics that can be extracted from using Stata.
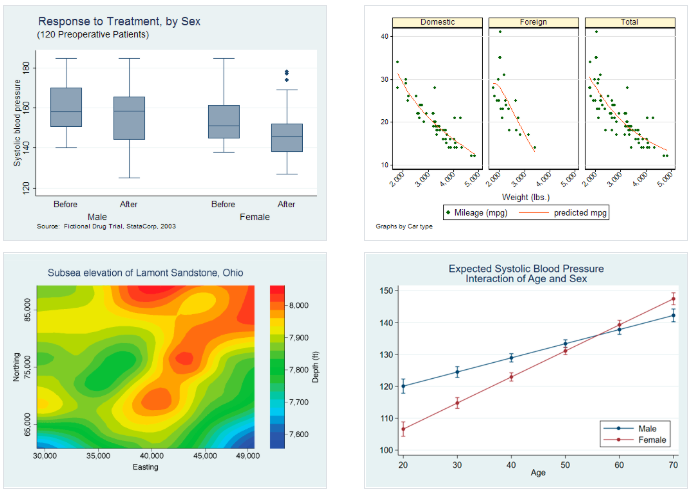
Fig. 3: Few examples of graphical outputs from Stata (adapted from www.stata.com)
Stata is very well supported by the StataCorp organisation as well as documentation on professional communities worldwide. StataCorp sends out updated files and fixes for reported glitches every two months on an average. The professional community also provides incredible support to the users of Stata. It allows the third party written commands to be directly sourced and loaded on the software. Hence, it poses itself as a very useful for someone who wants to extensively use for dissertation work.