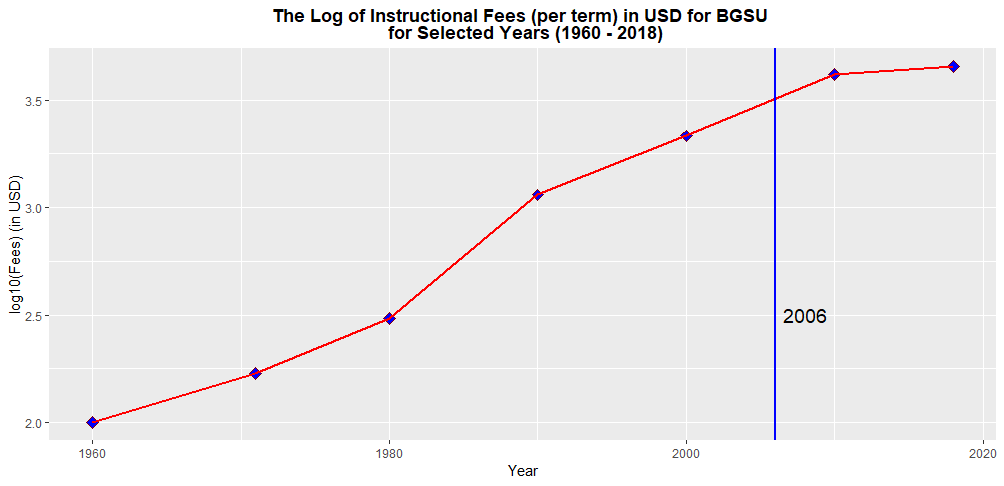
I obtained the data set from the Broadway CSV library. The data set is about Broadway shows, grouped over weeklong periods. The data set contains 12 variables including the name of the production, attendance, year, theater, type (whether it is a “Musical”, “Play”, or “Special”) and so on.
I am interested in comparing the best Broadway shows for the two time intervals such as 2000 – 2008, and 2009 – 2016. Further, I defined the best Broadway shows in terms of the total attendance (in million) who attended performances over the week.
Firstly, I constructed the grouped bar graph which can be improved to the certain extent. The horizontal axis represent the type of shows (show name) and the vertical axis represents the total number of attendance (in million).

It can be clearly seen, that the above graph needs an improvement. Because, it reflects too many show names (The name of the production) as a consequence, the show names are not visually prominent. Also, the graph does not have the title and axis labels are not clear.
Thus, I decided to look at the show which has only certain minimum number of attendance 2 million people. Further, I put the show names on the vertical side and the total number of attendance (in million) on the horizontal side. Also, I sorted the bars based on the total attendance (in million). In addition to this, I have also added the axis labels and title to the graph. Then I re-constructed the above graph by correcting the above mistakes in the following way.

I compared 16 different shows in two different time periods. According to the above graph, we can say that “The Lion King” was the most popular show in 2000-2008 period and there were nearly 6.36 million attendees for this show. However, “Wicked” was the popular show among people during the period from 2009-2016, where approximately 5.65 million people watched this show, whereas “The Lion King” was the second most popular show during this time.
My second graph is stack bar graph, which is given below. It is clearly evident, that this graph needs an improvement. For example, the labels on the horizontal axis are not clear and the graph does not process the title. Another, disadvantage of this graph is that the total on each columns are not the same. Thus, there is a room to improve this graph.

I improved the stack bar graph by correcting the above mentioned mistakes in the following way. I included the total number of people (in million) in each bar. Also, I improved the above graph by putting the show name on the vertical axis and the total attendance (in million) on the horizontal axis. The improved stack bar graph is given below.

According to the above graph, it can be clearly seen, the most popular show was “The Lion king” in 2000-2008 period which was watched by 6.36 million people whereas this was the second most popular show during the 2009-2016 period. Further, approximately 5.65 million watched “Wicked” show, this was the most popular show during the 2009-2016 period.
Moreover, I improved the stack graph by constructing the 100% stacked graph, which shows the percentage of the whole of each time period and are plotted by the percentage of each value to the total amount in each time period. This makes it easier to see the relative differences between the shows in each time period. I portrayed them in percentage of the total in the following manner.


























 I incorporate the following attributes which may affects the visual clarity of the above graph.
I incorporate the following attributes which may affects the visual clarity of the above graph.